Talk Data to Me: Legacy Data
I recently gave a talk at General Assembly about data within civic tech and smart cities for their “Talk Data to Me” speaker series. Here are the slides from that talk. The talk focused on the legacy data project I have been leading with Jennifer Clark.
In the talk, I highlighted the challenge of wrangling legacy open government data (OGD 1) to make it into machine-processable OGD. By wrangling, I mean the processes through which data are made useful by extracting, scraping, manipulating, reformatting, and digesting it, amongst other things. Within the project, I consider a few particular subprocesses of wrangling, such as collection (e.g. identifying the corpus of data from which to pull a subset), extraction and synthesis (e.g. pulling data out of a file and generating any necessary missing data), schematization and normalization (e.g. making the data adhere to an organizational architecture and standard data entry formats), and documentation (e.g. creating metadata, transactional data, information architectures, and so forth).
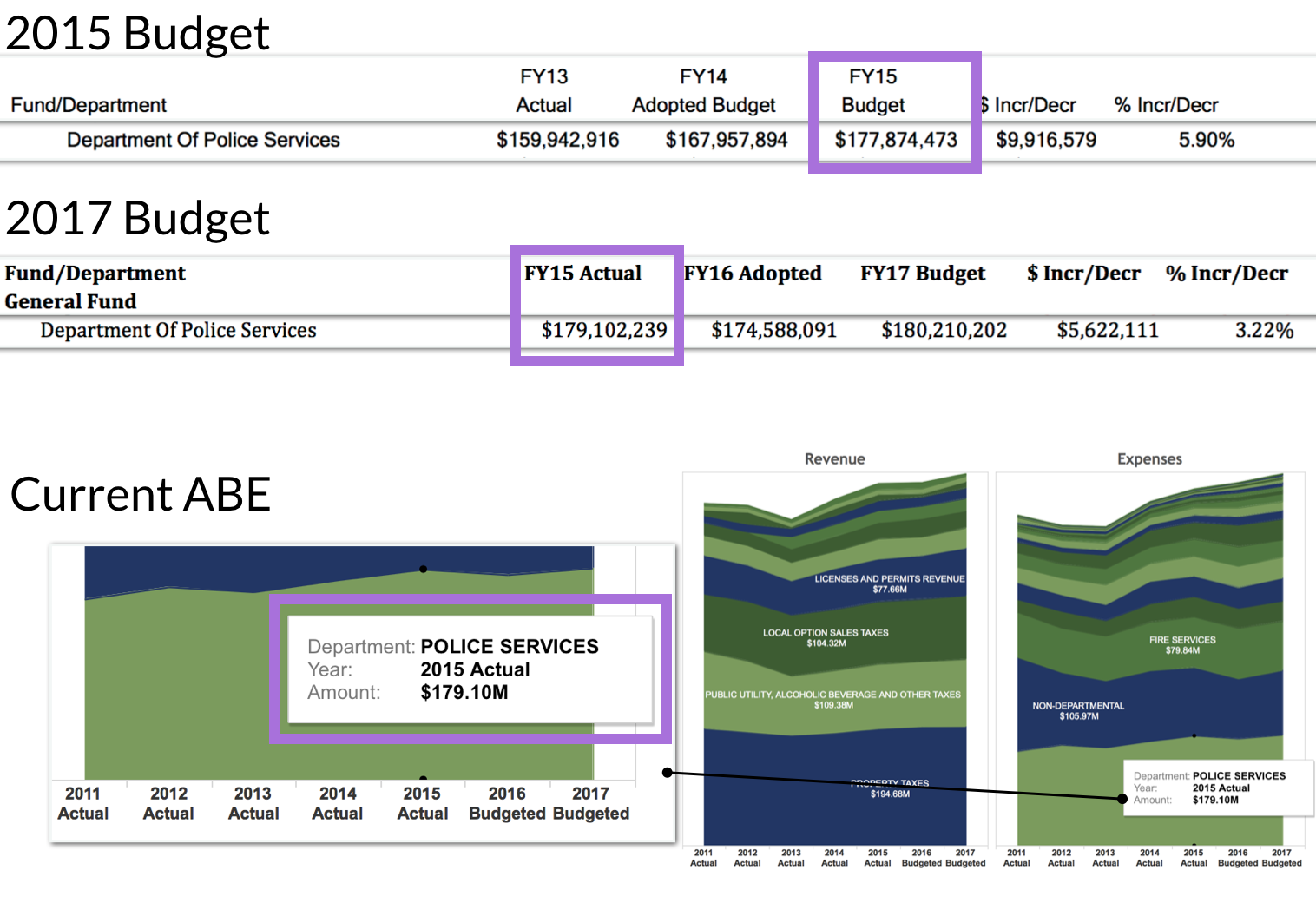
In the talk, I shared some insights related to collection and extraction with regards to OGD, specifically related to the corpus of budget data from the City of Atlanta. These data are currently released through PDFs and, therefore, hard to make use of in machine-applications. The emphasis of the talk was on the value claim that OGD increases transparency, and I argue that increased transparency is a matter of what question drives the release of data. For the City of Atlanta, the budget OGD effort seems to focus on the question “What did the Atlanta spend year-by-year?” as the main budget OGD portal—the Atlanta Budget Explorer—actually releases audited spending and revenue data from the Comprehensive Annual Financial Review (or CAFR). Another question—the one motivating the legacy data project—is “Did Atlanta city government uphold its budgetary promises each year?” In the latter instance, different data are necessary, namely, budget AND audited spending/revenue data. As such, collection and extraction are motivated by a specific idea of what constitutes transparency (currently: showing what was actually spent), and OGD efforts need to be interrogated beyond their broad value claims.
Footnotes
-
Open data are defined “as non-privacy-restricted and non-confidential data which is [sic] produced with public money and is [sic] made avail- able without any restrictions on its usage or distribution. […] Data can be provided by public and private organizations, as the essence is that the data is [sic] funded by public money.” (Janssen et al. 2012) Open government data, or OGD, are those open data produced specifically by government institutions in their transactions as government institutions.
Citation: Janssen, Marijn, Yannis Charalabidis, and Anneke Zuiderwijk. 2012. “Benefits, Adoption Barriers and Myths of Open Data and Open Government.” Information Systems Management 29 (4): 258–268. ↩